


Tecnologías de detección óptica de imagen y visualización en 3D se han investigado extensamente en campos tan diversos como la difusión de televisión, entretenimiento, ciencias médicas, y la robótica. 1-4 Una prometedora tecnología de imagen integral, es un método de imagen 3D autoestereoscópico que ofrece una pasiva y relativamente forma barata para capturar información 3D y visualizarlo óptica o computacionalmente. 5-7 imágenes Integral pertenece a la clase más amplia de técnicas de imagen multi-vista que permiten un análisis en profundidad desde tres puntos de vista: equipo de música, tiempo de vuelo, y structured- estrategias de luz. 8 imágenes Integral también se ha utilizado para las tareas de clasificación. 9 Sin embargo, son los primeros en aplicarlo al reconocimiento acción. 10, 11
 Imágenes Integral proporciona el perfil 3D y el rango de los objetos en una escena utilizando un conjunto de sensores de imagen de alta resolución o en un modo de apertura sintética (ver Figura 1 ). Cuando un solo sensor captura múltiples imágenes en 2D, es posible obtener mayor campo de visión (FOV) de imágenes 2D. En el modo de imagen integral de apertura sintética que utilizamos, una serie de sensores se distribuyen en una cuadrícula, o un solo sensor se mueve a las posiciones en la parrilla. La distancia horizontal o vertical entre dos de estas posiciones se llama el paso (p). La imagen de reconstrucción 3D se puede lograr mediante computacionalmente que simula la espalda-óptico de proyección de las imágenes elementales. En la Figura 1 , c x y c v son los tamaños horizontales y verticales del sensor y f su longitud focal. Se utilizó una, matriz de agujero de alfiler ordenador virtual sintetizado para mapear inversamente las imágenes elementales en el espacio de objetos (véase la Figura 1 ). Superposición de las imágenes elementales adecuadamente desplazado crearon el 3D reconstruido imágenes.
Imágenes Integral proporciona el perfil 3D y el rango de los objetos en una escena utilizando un conjunto de sensores de imagen de alta resolución o en un modo de apertura sintética (ver Figura 1 ). Cuando un solo sensor captura múltiples imágenes en 2D, es posible obtener mayor campo de visión (FOV) de imágenes 2D. En el modo de imagen integral de apertura sintética que utilizamos, una serie de sensores se distribuyen en una cuadrícula, o un solo sensor se mueve a las posiciones en la parrilla. La distancia horizontal o vertical entre dos de estas posiciones se llama el paso (p). La imagen de reconstrucción 3D se puede lograr mediante computacionalmente que simula la espalda-óptico de proyección de las imágenes elementales. En la Figura 1 , c x y c v son los tamaños horizontales y verticales del sensor y f su longitud focal. Se utilizó una, matriz de agujero de alfiler ordenador virtual sintetizado para mapear inversamente las imágenes elementales en el espacio de objetos (véase la Figura 1 ). Superposición de las imágenes elementales adecuadamente desplazado crearon el 3D reconstruido imágenes.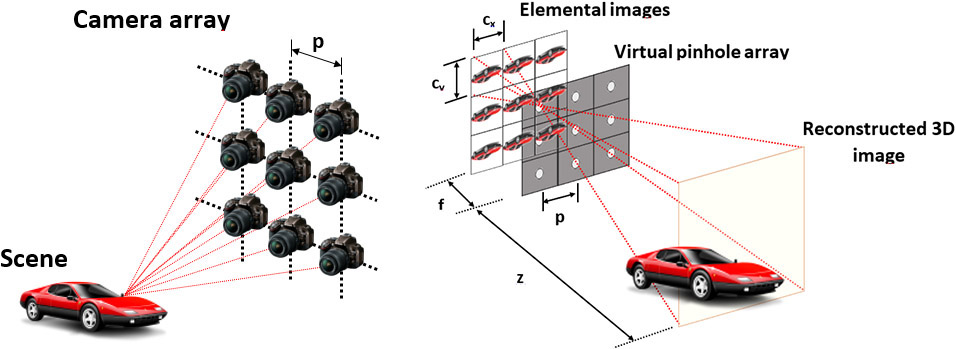
Figura 1. adquisición de imagen integral de apertura sintética y método de reconstrucción computacional. Pitch (p) es la distancia entre los centros de sensor (izquierda), c x y c v representan los tamaños horizontales y verticales del sensor, y f es la longitud focal sensor (derecha).
Nuestra metodología se basa en la adquisición de los vídeos en 3D de gestos con las manos usando un sistema de imagen integral formada por una matriz de 3 × 3 cámaras. Se analizó el potencial de reconocimiento de gestos utilizando imágenes 3D integral y compararon los resultados con los vídeos de una sola cámara en 2D. Procesamos representaciones reconstruidas seccionales de los objetos en la escena utilizando estrategias de reconocimiento de gestos. Creemos que los experimentos proporcionan evidencia de la viabilidad de reconocimiento de gestos con imagen integral.
Nuestra configuración incluye una matriz de 3 × 3 de las cámaras Stingray F080B / C. El uso de un IEEE 1394 de comunicación de alta velocidad de bus de serie, capturamos nueve vídeos sincronizados a 15 fps y una resolución de 1024 × 768 píxeles. Estamos posteriormente rectificamos los vídeos adquiridos. 12 A continuación, adquirimos dos representaciones de tres gestos diferentes a partir de 10 personas. Capturamos los tres gestos, que se hicieron al extender el brazo derecho: fuimos, negamos, y abrir y cerrar la mano (ver Figura 2 ). 10,11 Cada lente de la cámara se centró en un avión a punto de 2m de distancia. La profundidad de campo permitido para todos los objetos y personas de 0,5 a 3,5 m de distancia de estar en el foco. Las 10 personas que estaban a punto de 2,5 m delante del conjunto de cámaras. Adquirimos sus gestos en un laboratorio sin otros movimientos. Se registraron 60 vídeos correspondientes a las tres acciones las 10 personas realizan dos veces. El volumen 3D para su primer cuadro fue reconstruida para inferir la distancia a la que la mano estaba en el foco. A continuación, esta distancia se utilizó para reconstruir el volumen de los marcos restantes. Hicimos la reconstrucción de 1 a 3,5 m en 10mm pasos. La figura 2 muestra el plano reconstruida donde la acción está en el foco de los tres gestos diferentes que hemos considerado.

Figura 2. Tres gestos utilizados en nuestra investigación. Izquierda: Gesto de Izquierda. Secundaria: Denegar gesto. Derecha: Open cerca gesto /.
El método para la caracterización y el reconocimiento de gestos se puede resumir de la siguiente manera: 13 de generación y caracterización puntos de interés espacio-temporales (Stips) para cada vídeo (ver Figura 3 ); 10,11cuantificar los descriptores que resulta en un número de palabras visuales (también llamado el libro de códigos ); la creación de una bolsa de palabras (proa) representación para cada video usando sus PITS y el libro de códigos resultante; y clasificar los vídeos no vistos desde sus representaciones arco.

Figura 3. Los ejemplos de los puntos de interés (espacio-temporales Stips) detectados (círculos amarillos) a los tres marcos diferentes en el "abierto" de vídeo gesto. Los diferentes tamaños círculo representan la escala de detección de cada STIP.
Generamos PITS y, de ellos, histogramas de gradientes orientados (HOG) y de flujo óptico (HOF). Nos cuantificados estos histogramas en palabras visuales a través de k-means clustering. Representamos a cada vídeo mediante la creación de un histograma de palabras de código. 14 Para evaluar el rendimiento de reconocimiento de gestos, seguimos un protocolo 'leave-one-sujeto-out'. 15, 16 Elegimos máquinas de vectores soporte como método de reconocimiento de patrones para la clasificación de los gestos .17 Nuestros resultados mostraron 10 que de imagen integral superó adquisición con la cámara central de la matriz 3 × 3 al comparar el mejor descriptor en cada caso (HOF para monocular y HOF + HOG de imagen integral).
En resumen, la información 3D muestra potencial en la mejora de la precisión de reconocimiento de gestos humanos. Imágenes Integral nos permite reconstruir una escena 3D sólo para los aviones en los que aparece preferentemente el gesto. Esto abre la puerta a la aplicación de estrategias de reconocimiento que antes no eran posibles y, finalmente, a un aumento sustancialmente la capacidad de reconocimiento. Nuestro próximo paso será computacionalmente paralelizar todo el proceso para que pueda ser aplicado casi en tiempo real y utilizar otros descriptores de reconocimiento de gestos que explotan las capacidades de enfoque de imagen integral.
Pedro Latorre-Carmona
Filiberto Pla, y Eva Salvador-Balaguer
Instituto de Nuevas Tecnologías de la Imagen
Universitat Jaume I
Castell'on de la Plana, España Pedro Latorre-Carmona es un investigador postdoctoral cuyos intereses son imágenes 3D integral, reconocimiento de patrones, la visualización de fotones de hambre, y el procesamiento de imágenes multiespectrales.
Universitat Jaume I
Castell'on de la Plana, España Pedro Latorre-Carmona es un investigador postdoctoral cuyos intereses son imágenes 3D integral, reconocimiento de patrones, la visualización de fotones de hambre, y el procesamiento de imágenes multiespectrales.
Bahram Javidi
Departamento de Ingeniería Eléctrica y Computación
de la Universidad de Connecticut
de la Universidad de Connecticut
Storrs, CT
Bahram Javidi recibió su licenciatura de la Universidad George Washington y una maestría y doctorado de la Universidad Estatal de Pennsylvania, todos en ingeniería eléctrica. Él es el Patronato Profesor Distinguido en la Universidad de Connecticut. Tiene más de 900 publicaciones, incluyendo más de 400 artículos revisados por pares de revistas y más de 440 actas de congresos, entre ellos unos 120 direcciones plenarias, conferencias magistrales y ponencias invitadas.
Referencias:
1. X. Xiao, B. Javidi, M. Martínez-Corral, A. Stern, avances en la imagen integral 3D: detección, la pantalla y las aplicaciones, Appl. . Opt 52 (4), p. 546-560, 2013.
2. M. Cho, M. Daneshpanah, I. Luna, B. Javidi, detección óptica 3D y visualización utilizando imágenes integral, Proc. IEEE 99 (4), p. 556-575, 2011.
3. R. Martínez-Cuenca, G. Saavedra, M. Martínez-Corral, B. Javidi, Progreso en pantalla multiperspectiva 3D de imagen integral, Proc. IEEE 97 (6), p. 1067-1077, 2009.
4. J.-Y. Hijo, W.-H. Hijo, S.-K. Kim, K.-H. Lee, B. Javidi, imágenes en 3D para la creación de entornos del mundo real-como, Proc. IEEE 101 (1), p. 190-205, 2013.
5. J. Arai, F. Okano, M. Kawakita, M. Okui, Y. Haino, M. Yohimura, M. Furuya, M. Sato, televisión 3D Integral utilizando un sistema de imagen de 33 megapíxeles, J. Display Technol. 6 (10), p. 422-430, 2010.
6. HH Tran, H. Suenaga, K. Kuwana, K. Masamune, T. Dohi, S. Nakajima, H. Liao, sistema de realidad aumentada para la cirugía oral usando la visualización estereoscópica 3D, Lect.Notas Comput. Sci. 6891, p. 81-88, 2011.
7. H. Liao, T. Inomata, I. Sakuma, T. Dohi, realidad aumentada 3D para cirugía guiada por RM utilizando integral autoestereoscópico videografía superposición de imágenes, IEEE Trans. Biomed. Eng. 57 (6), p. 1476-1486, 2010.
8. L. Chen, H. Wei, J. Barquero, un estudio de análisis de movimiento humano utilizando imágenes de fondo, patrón Recognit. Lett. 34, p. 1995-2006, 2013.
9. CM Do, R. Martínez-Cuenca, B. Javidi, reconocimiento de objetos distorsión tolerante 3D para imagen integral mediante análisis de componentes independientes, J. Opt. Soc. Am. A26, p. 245-251, 2009.
10. V. Javier Traver, P. Latorre-Carmona, E. Salvador-Balaguer, F. Pla, B. Javidi, reconocimiento de gestos humano utilizando imágenes 3D integral, J. Opt. Soc. Am. A 31, p.2312-2320, 2014.
11. P. Latorre Carmona, E. Salvador-Balaguer, F. Pla, B. Javidi, la adquisición de imágenes y procesamiento Integral para el reconocimiento de gestos humanos, Proc. SPIE 9495, 2015. (Trabajo invitado.)
12. Z. Zhang, una nueva técnica flexible para calibración de la cámara, IEEE Trans. Patrón anal. Mach. . Intell 22, p. 1330-1334, 2000.
13. H. Wang, MM Ullah, A. Klaser, I. Laptev, C. Schmid, Evaluación de las características locales espacio-temporales para el reconocimiento de la acción, Br. Mach. Vis. Conf. de 2009.
14. I. Laptev, En los puntos de interés del espacio-tiempo, Int'l J. Comput. Vis. 64, p. 107-123, 2005.
15. K. Schindler, LJV Gool, fragmentos de acción: el número de fotogramas que hace necesario reconocer la acción humana ?, IEEE Conf. Comput. Vis. Patrón Recognit. CVPR, 2008.
16. Z. Lin, Jiang Z., LS Davis, Reconociendo las acciones humanas por el aprendizaje y el juego árboles prototipo forma de movimiento, IEEE Trans. Patrón anal. Mach. . Intell 34, p.533-547, 2012.
17. N. Cristianini, J. Shawe-Taylor, Introducción a apoyar Máquinas de Vectores y métodos de aprendizaje basado en el kernel Otros , Cambridge University Press, 2000.









0 comentarios :
Publicar un comentario